Add generated code samples, detail compilation
This commit is contained in:
parent
c9773681cf
commit
b1e3d488a5
6 changed files with 96 additions and 35 deletions
report
|
|
@ -1,4 +1 @@
|
|||
- Add a sample of geenrated code?
|
||||
- Explicitly tell that we only support unwinding, and this only for a few
|
||||
registers
|
||||
- Make consistant -ise / -ize (eg. optimize)
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
Before 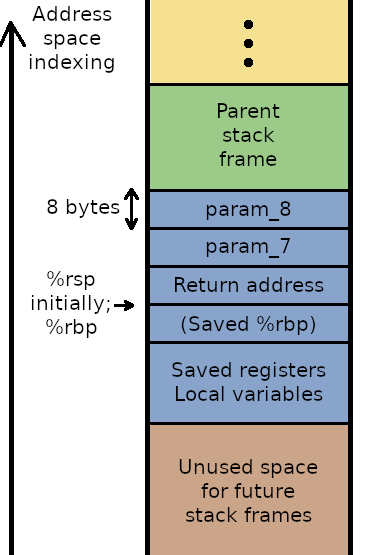
(image error) Size: 34 KiB After 
(image error) Size: 37 KiB
|
Binary file not shown.
|
|
@ -121,10 +121,24 @@ from the whole stack.
|
|||
|
||||
Interpreting a frame in order to get the machine state \emph{before} this
|
||||
frame, and thus be able to decode the next frame recursively, is called
|
||||
\emph{unwinding} a frame. For all the reasons above and more, it is often
|
||||
necessary to have additional data to perform stack unwinding. This data is
|
||||
often stored among the debugging informations of a program, and one common
|
||||
format of debugging data is DWARF\@.
|
||||
\emph{unwinding} a frame.
|
||||
|
||||
Let us consider a stack with x86\_64 calling conventions, such as shown in
|
||||
Figure~\ref{fig:call_stack}. Assuming the compiler decided here \emph{not} to
|
||||
use \reg{rbp}, and assuming the function \eg{} allocates a buffer of 8
|
||||
integers, the area allocated for local variables should be at least $32$ bytes
|
||||
long (for 4-bytes integers), and \reg{rip} will be pointing below this area.
|
||||
Left apart analyzing the assembly code produced, there is no way to find where
|
||||
the return address is stored, relatively to \reg{rsp}, at some arbitrary point
|
||||
of the function. Even when \reg{rbp} is used, there is no easy way to guess
|
||||
where each callee-saved register is stored in the stack frame, and worse, which
|
||||
callee-saved registers were saved (since it is not necessary to save a register
|
||||
that the function never touches).
|
||||
|
||||
With this example, it seems pretty clear that it is often necessary to have
|
||||
additional data to perform stack unwinding. This data is often stored among the
|
||||
debugging informations of a program, and one common format of debugging data is
|
||||
DWARF\@.
|
||||
|
||||
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
||||
\subsection{Unwinding usage and frequency}
|
||||
|
|
@ -574,16 +588,24 @@ machine code on the x86\_64 platform.
|
|||
The rough idea of the compilation is to produce, out of the \ehframe{} section
|
||||
of a binary, C code that resembles the code shown in the DWARF semantics from
|
||||
Section~\ref{sec:semantics} above. This C code is then compiled by GCC,
|
||||
providing for free all the optimisation passes of a modern compiler. This code
|
||||
is compiled as a shared library, containing a single function, taking as
|
||||
argument an instruction pointer and a memory context (\ie{} the value of the
|
||||
various machine registers) as defined in Listing~\ref{lst:unw_ctx}. An
|
||||
optionally enabled parameter can be used to pass a function pointer to a
|
||||
providing for free all the optimization passes of a modern compiler.
|
||||
|
||||
The generated code consists in a single monolithic function, taking as
|
||||
arguments an instruction pointer and a memory context (\ie{} the value of the
|
||||
various machine registers) as defined in Listing~\ref{lst:unw_ctx}. The
|
||||
function will then return a fresh memory context, containing the values the
|
||||
registers hold after unwinding this frame.
|
||||
|
||||
The body of the function itself is mostly a huge switch, taking advantage of
|
||||
the non-standard ---~yet widely implemented in C compilers~--- syntax for range
|
||||
switches, in which each \lstc{case} can refer to a range. All the FDEs are
|
||||
merged together into this switch, each row of a FDE being a switch case. The
|
||||
cases then fill a context with unwound values, then return it.
|
||||
|
||||
An optionally enabled parameter can be used to pass a function pointer to a
|
||||
dereferencing function, that conceptually does what the dereferencing \lstc{*}
|
||||
operator does on a pointer, and is used to unwind a process that is not the
|
||||
currently running process, and thus not sharing the same address space. A call
|
||||
to this function returns a fresh memory context, containing the values the
|
||||
registers hold after unwinding this frame.
|
||||
|
||||
Unlike in the \ehframe, and unlike what should be done in a release,
|
||||
real-world-proof version of the \ehelfs, the choice was made to keep this
|
||||
|
|
@ -614,9 +636,17 @@ options turned on or off, and it doesn't require to alter the base system by
|
|||
editing \eg{} \texttt{/usr/lib/libc-*.so}. Instead, when the \ehelf{} data is
|
||||
required, those files can simply be \lstc{dlopen}'d.
|
||||
|
||||
\todo{Talk about switch structure, considered and ignored registers, etc.}
|
||||
\medskip
|
||||
|
||||
\todo{More details here? Is it necessary or just too technical?}
|
||||
\lstinputlisting[language=C, caption={\ehelf{} for the previous example},
|
||||
label={lst:fib7_eh_elf_basic}]
|
||||
{src/fib7/fib7.eh_elf_basic.c}
|
||||
|
||||
\note{I did not put some ASM here, as I doubt the jury will read it anyway, }\\
|
||||
\qnote{and it takes way too much space}
|
||||
|
||||
The C code in Listing~\ref{lst:fib7_eh_elf_basic} is a part of what was
|
||||
generated for the C code in Listing~\ref{lst:ex1_c}.
|
||||
|
||||
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
||||
\subsection{First results}
|
||||
|
|
@ -682,20 +712,29 @@ made in order to shrink the \ehelfs.
|
|||
|
||||
\medskip
|
||||
|
||||
The major optimization that most reduced the output size was to use a more
|
||||
flexible if/else if tree implementing a binary search on the program counter
|
||||
relevant intervals, instead of a huge switch. In the process, we also
|
||||
\emph{outline} a lot of code, that is, find out identical code blocks, move
|
||||
them outside of the if/else tree, identify them by a label, and jump to them
|
||||
using a \lstc{goto}, which de-duplicates a lot of code and contributes greatly
|
||||
to the shrinking. In the process, we noticed that the vast majority of FDE rows
|
||||
are actually taken among very few ``common'' FDE rows.
|
||||
The major optimization that most reduced the output size was to use an if/else
|
||||
tree implementing a binary search on the program counter relevant intervals,
|
||||
instead of a huge switch. In the process, we also \emph{outline} a lot of code,
|
||||
that is, find out identical code blocks, move them outside of the if/else tree,
|
||||
identify them by a label, and jump to them using a \lstc{goto}, which
|
||||
de-duplicates a lot of code and contributes greatly to the shrinking. In the
|
||||
process, we noticed that the vast majority of FDE rows are actually taken among
|
||||
very few ``common'' FDE rows.
|
||||
|
||||
This makes this optimisation really efficient, as seen later in
|
||||
This makes this optimization really efficient, as seen later in
|
||||
Section~\ref{ssec:results_size}, but also makes it an interesting question ---
|
||||
not investigated during this internship --- to find out whether standard DWARF
|
||||
data could be efficiently compressed in this way.
|
||||
|
||||
\begin{minipage}{0.45\textwidth}
|
||||
\lstinputlisting[language=C, caption={\ehelf{} for the previous example},
|
||||
label={lst:fib7_eh_elf_outline},
|
||||
lastline=18]
|
||||
{src/fib7/fib7.eh_elf_outline.c}
|
||||
\end{minipage} \hfill \begin{minipage}{0.45\textwidth}
|
||||
\lstinputlisting[language=C, firstnumber=last, firstline=19]
|
||||
{src/fib7/fib7.eh_elf_outline.c}
|
||||
\end{minipage}
|
||||
|
||||
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
||||
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
|
||||
|
|
|
|||
|
|
@ -1,21 +1,13 @@
|
|||
unwind_context_t _eh_elf(unwind_context_t ctx, uintptr_t pc) {
|
||||
unwind_context_t out_ctx;
|
||||
switch(pc) {
|
||||
// [...] Previous FDEs redacted for brevity
|
||||
case 0x615 ... 0x618:
|
||||
out_ctx.rsp = ctx.rsp + (8);
|
||||
out_ctx.rip = *((uintptr_t*)(out_ctx.rsp + (-8)));
|
||||
out_ctx.flags = 3u;
|
||||
return out_ctx;
|
||||
case 0x619 ... 0x658:
|
||||
out_ctx.rsp = ctx.rsp + (48);
|
||||
out_ctx.rip = *((uintptr_t*)(out_ctx.rsp + (-8)));
|
||||
out_ctx.flags = 3u;
|
||||
return out_ctx;
|
||||
case 0x659 ... 0x659:
|
||||
out_ctx.rsp = ctx.rsp + (8);
|
||||
out_ctx.rip = *((uintptr_t*)(out_ctx.rsp + (-8)));
|
||||
out_ctx.flags = 3u;
|
||||
return out_ctx;
|
||||
// [...] Further lines and FDEs redacted for brevity
|
||||
default:
|
||||
out_ctx.flags = 128u;
|
||||
return out_ctx;
|
||||
33
report/src/fib7/fib7.eh_elf_outline.c
Normal file
33
report/src/fib7/fib7.eh_elf_outline.c
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
unwind_context_t _eh_elf(unwind_context_t ctx, uintptr_t pc) {
|
||||
unwind_context_t out_ctx;
|
||||
if(pc < 0x619) {
|
||||
// IP=0x615 ... 0x618
|
||||
goto _factor_3;
|
||||
} else {
|
||||
if(pc < 0x659) {
|
||||
// IP=0x619 ... 0x658
|
||||
goto _factor_4;
|
||||
} else {
|
||||
// IP=0x659 ... 0x659
|
||||
goto _factor_3;
|
||||
}
|
||||
}
|
||||
|
||||
_factor_default:
|
||||
out_ctx.flags = 128u;
|
||||
return out_ctx;
|
||||
|
||||
/* ===== LABELS ======== */
|
||||
|
||||
_factor_4:
|
||||
out_ctx.rsp = ctx.rsp + (48);
|
||||
out_ctx.rip = *((uintptr_t*)(out_ctx.rsp + (-8)));
|
||||
out_ctx.flags = 3u;
|
||||
return out_ctx;
|
||||
|
||||
_factor_3:
|
||||
out_ctx.rsp = ctx.rsp + (8);
|
||||
out_ctx.rip = *((uintptr_t*)(out_ctx.rsp + (-8)));
|
||||
out_ctx.flags = 3u;
|
||||
return out_ctx;
|
||||
}
|
||||
Loading…
Add table
Reference in a new issue